Samsung introduce TRUEBench per testare la produttività dell'AI in scenari di lavoro reali
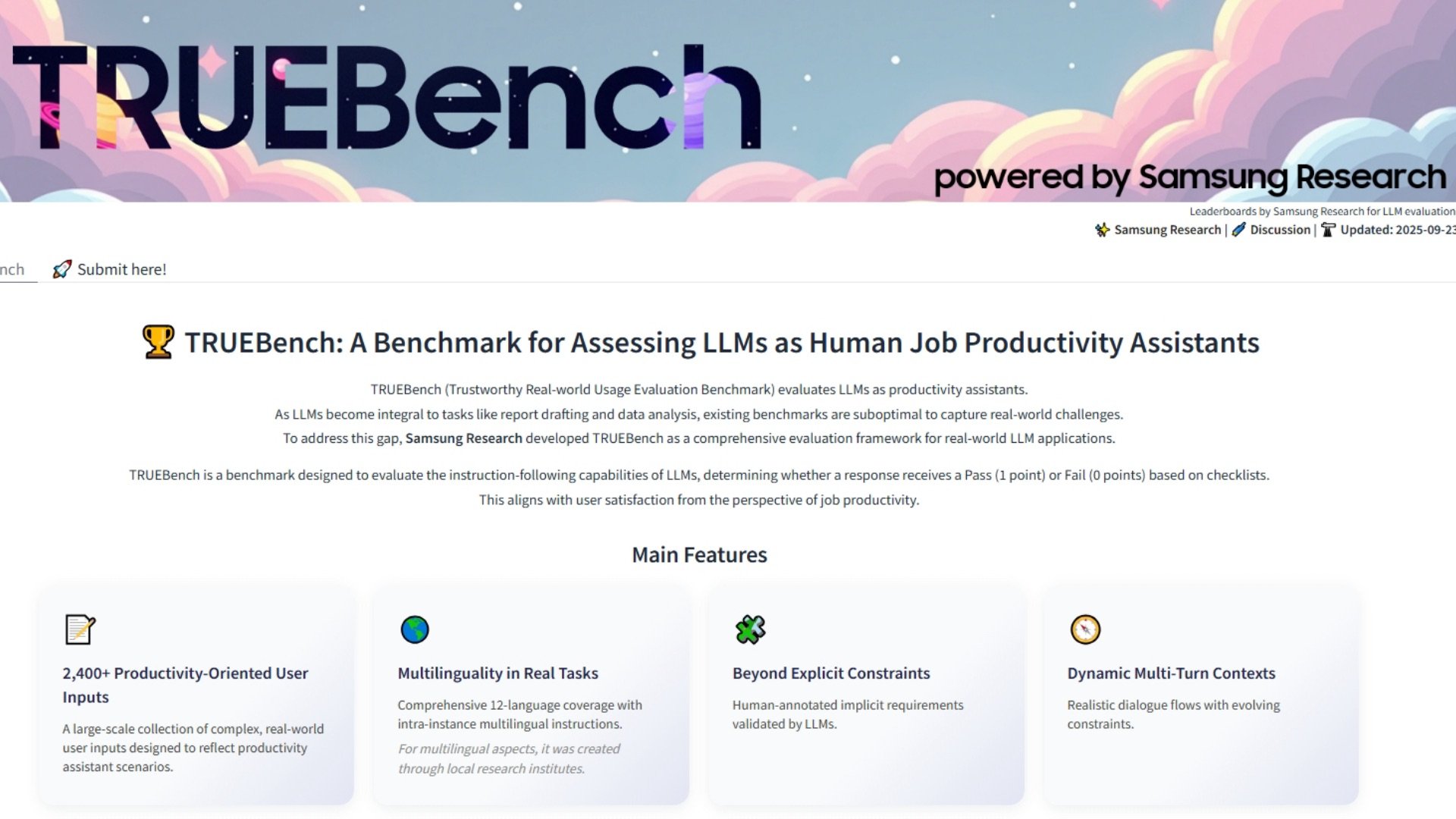
L'INTELLIGENZA ARTIFICIALE i benchmark hanno a lungo faticato a catturare ciò che le persone fanno realmente con questi sistemi. La maggior parte dei test si concentra ancora su compiti di domanda e risposta solo in inglese, che sembrano ordinati sulla carta, ma non riflettono la varietà di attività su cui si fa affidamento nel lavoro quotidiano. Samsung ha appena lanciato https://news.samsung.com/global/samsung-introduces-truebench-a-benchmark-for-real-world-ai-productivityTRUEBench, acronimo di Trustworthy Real-world Usage Evaluation Benchmark, per misurare le prestazioni dell'IA in modi che si avvicinano di più ai compiti reali in ufficio.
TRUEBench va oltre i semplici trivia o gli scambi di un singolo prompt per far funzionare i modelli attraverso il riassunto di documenti, la traduzione in dodici lingue, l'analisi dei dati e le istruzioni in più fasi che richiedono all'AI di mantenere il contesto. Samsung ha sviluppato 2.485 set di test in dieci categorie e 46 sottocategorie, con input che vanno da una manciata di caratteri a più di ventimila. L'obiettivo è simulare tutto, dai comandi rapidi ai lunghi rapporti commerciali.
Paul (Kyungwhoon) Cheun, CTO della Divisione DX di Samsung Electronics e Responsabile di Samsung Research, ha dichiarato: "Samsung Research apporta una profonda competenza e un vantaggio competitivo grazie alla sua esperienza di AI nel mondo reale. Ci aspettiamo che TRUEBench stabilisca degli standard di valutazione per la produttività e consolidi la leadership tecnologica di Samsung"
Affinché un modello passi, deve soddisfare tutte le condizioni richieste in un test, comprese quelle implicite che riflettono ciò che una persona ragionevole si aspetterebbe anche se tali condizioni non sono esplicitate. Questo metodo "tutto o niente" rende i risultati meno indulgenti, ma li avvicina anche al modo in cui si decide se un risultato è veramente utile. Samsung ha creato le regole combinando l'input umano con i controlli dell'AI. Gli annotatori umani hanno redatto le condizioni iniziali, l'AI ha segnalato contraddizioni o incongruenze, e gli umani hanno perfezionato nuovamente il quadro prima di bloccarlo. Una volta finalizzata, la valutazione poteva essere eseguita su scala attraverso il punteggio automatico dell'AI.
Samsung ha anche reso pubblici il set di dati, le classifiche e le statistiche di output attraverso Hugging Face. È possibile confrontare direttamente fino a cinque modelli e vedere come si posizionano i loro risultati. Questo livello di trasparenza consente agli sviluppatori, ai ricercatori e agli utenti di esaminare il benchmark piuttosto che fidarsi semplicemente delle affermazioni di Samsung.
Tuttavia, il benchmark non è perfetto, in quanto la definizione delle regole conterrà sempre un certo grado di distorsione, e la richiesta di un successo completo in ogni condizione significa che le risposte parziali ma comunque utili vengono classificate come fallimenti. Il supporto linguistico va oltre la maggior parte dei test esistenti, ma le prestazioni saranno inevitabilmente diverse, soprattutto nelle lingue in cui i dati di formazione sono scarsi. Il set di test si orienta anche verso compiti aziendali generali, per cui domini altamente specializzati come la legge, la medicina o la ricerca scientifica potrebbero non essere pienamente rappresentati.
Fonte(i)

