CheckMag | Nessuna GPU, nessun problema. Ospitare il proprio LLM è infinitamente più divertente rispetto alle offerte censurate dei grandi operatori e funziona sorprendentemente bene.

Cosa succeda effettivamente ai suoi dati quando interroga un'intelligenza artificiale è praticamente impossibile da immaginare, ma qualsiasi cosa succeda, di certo non è più sua.
Accanto a generazione di immagini e alla generazione di video, se è desideroso di sperimentare i Large Language Models (LLM), ma non vuole consegnare i suoi dati alle grandi tecnologie, l'hosting è sorprendentemente facile e presenta diversi vantaggi rispetto ai grandi player.
In primo luogo, qualunque cosa decida di fare, tutti i suoi dati rimangono sotto il suo controllo, il che, se non è disposto a consegnare i suoi dati a Mechahitlerè un vantaggio immediato. Inoltre, può utilizzare praticamente tutti i modelli che desidera, che si tratti di Deepseek, Gemma2 o GPT, con l'ulteriore vantaggio di poter utilizzare versioni che non limitano i tipi di query che vi si possono inserire.
KoboldCPP è uno strumento di generazione di testo AI facile da usare e a esecuzione singola, progettato per eseguire i modelli linguistici di grandi dimensioni GGUF e GGML. Supporta sia GPU che CPU e può fungere da backend specializzato per la narrazione e la chat di AI. KoboldCPP può essere scaricato da GitHub qui ed è disponibile per Windows, Linux, Mac o Docker.
L'hosting in un container rende banale esporre l'LLM a tutti i dispositivi della rete, e ci sono modelli precostituiti per le principali piattaforme, tra cui Unraid e TrueNAS. Si può ottenere lo stesso risultato con altre installazioni, purché si aggiungano le regole necessarie al firewall.
Per iniziare
Una volta decisa la piattaforma di sua scelta, dovrà capire quale modello utilizzare. Hugging Face è il posto migliore per cercare i modelli, che dovranno essere in formato GGUF.
Se ha intenzione di ospitare scenari di D&D, vorrà sicuramente un modello non censurato, altrimenti l'LLM si rifiuterà di danneggiare i personaggi e potrà generare risultati indesiderati risultati indesiderati.
Alcuni modelli, come Deepseek e Claudehanno una propensione a "pensare", che in pratica vomita l'intero processo di pensiero della query. Questo potrebbe andare bene con una GPU che fa il lavoro pesante, ma senza una GPU il processo si rallenta notevolmente. Dovrà sperimentare con i modelli per trovarne uno che funzioni per lei, ma Gemma2 è un buon punto di partenza.
Trovi la pagina dei file e copi l'URL che rimanda al file GGUF. Molti modelli hanno dimensioni multiple, quindi dovrà sceglierne uno che si adatti ai limiti della sua RAM disponibile.
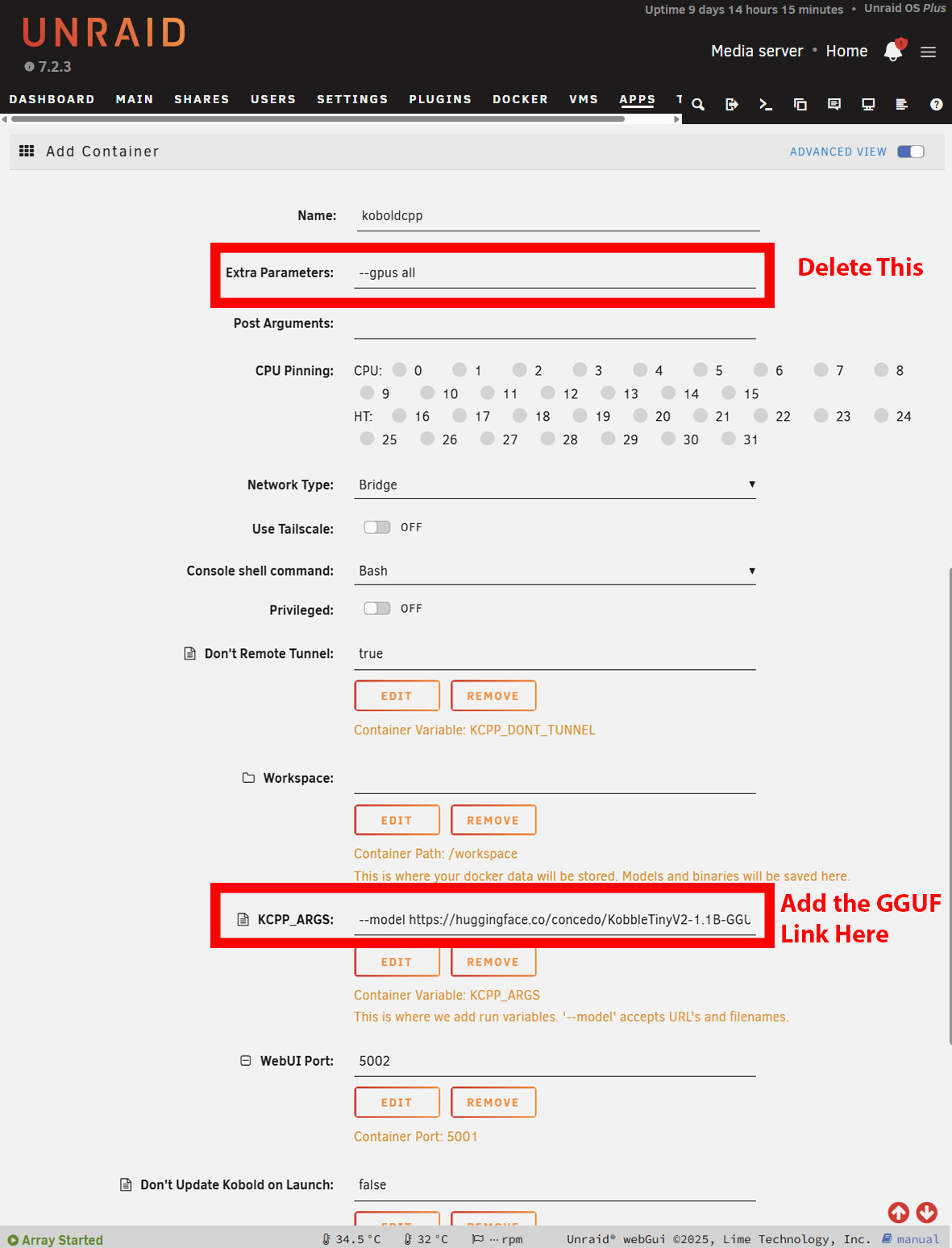
L'installazione su Windows è in gran parte la stessa. Tuttavia, dovrà scaricare la versione NoCUDA se si utilizza senza una GPU. L'avvio potrebbe richiedere un po' di tempo, poiché KoboldCPP scaricherà il modello prima di presentarle l'interfaccia. Su Windows, questo è ovvio, ma su Unraid o TrueNAS, dovrà aprire i registri per vedere l'avanzamento del download. Su Unraid, potrebbe essere necessario aumentare lo storage disponibile dei contenitori Docker lo spazio di archiviazione disponibile dei contenitori Docker, a seconda delle dimensioni del modello scelto.
KoboldCPP offre 4 diverse modalità di interfaccia, tra cui istruzione, storia, chat e avventura.
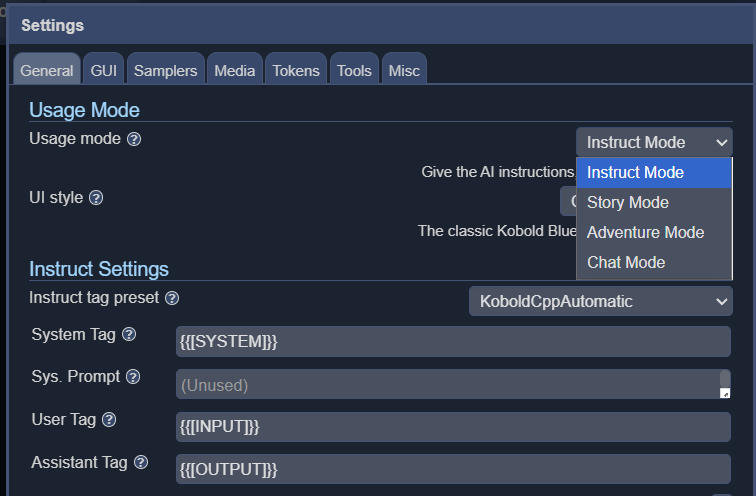
Sebbene non sia il più veloce in assoluto, il testo viene generato leggermente più lentamente rispetto alla velocità media di lettura. Perfettamente utilizzabile per gli scenari di D&D quando viene eseguito su un AMD 5950x a 16 core(disponibile su Amazon) e probabilmente funzionerà più velocemente su CPU più moderne. Più core può utilizzare, meglio è, e una quantità decente di RAM le permetterà di eseguire modelli più grandi, anche se dovrebbe andare bene con 16 GB. Anche le dimensioni e il tipo di modello avranno un impatto significativo sulla velocità di generazione, e la scelta di un modello più leggero può aumentare significativamente la velocità complessiva.
Ovviamente, per un'esperienza ottimale, l'esecuzione di modelli linguistici di grandi dimensioni con una GPU è ottimale, tuttavia, se desidera provare ad ospitare i propri, aggirando le restrizioni o le implicazioni sulla privacy dei dati di ChatGPT, Claude o Gemini, non ha bisogno di un hardware sofisticato per iniziare e può comunque ottenere un'esperienza decente.
Fonte(i)

