Una lingua sorprendente batte l'inglese e il cinese nei test LLM, secondo un nuovo studio accademico
Un nuovo studio multilingue che valuta come i modelli linguistici di grandi dimensioni gestiscono i documenti lunghi ha prodotto un'informazione inaspettata: Il polacco, non l'inglese o il cinese, mostra la massima accuratezza quando le finestre di contesto si estendono a 64.000 tokens e oltre. I risultati provengono dal benchmark OneRuler, introdotto in un documento COLM 2025che ha testato 26 lingue attraverso compiti di recupero e aggregazione.
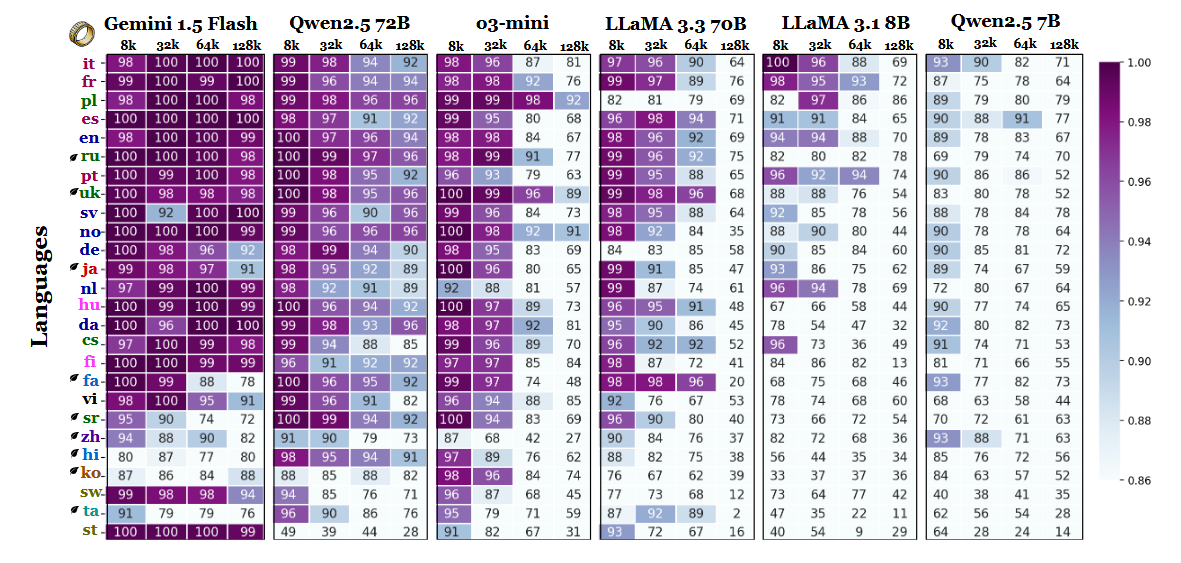
I ricercatori hanno confrontato l'accuratezza del modello con diverse lunghezze di contesto e hanno riscontrato un chiaro cambiamento quando le sequenze diventano più lunghe. Secondo il grafico dei risultati (a pagina 6), il polacco è in testa a tutte le lingue con un'accuratezza media dell'88% su scale di contesto lunghe. L'inglese scende al sesto posto e il cinese si colloca tra gli ultimi quattro.
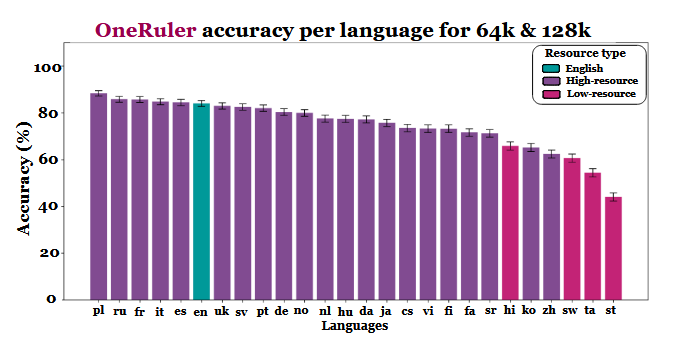
Lo studio suggerisce che la disparità potrebbe essere legata all'efficienza della tokenizzazione e alle differenze basate sulla scrittura, piuttosto che al semplice volume dei dati di formazione. Le lingue che utilizzano scritture basate sul latino - come il polacco, il francese e lo spagnolo - hanno costantemente ottenuto risultati migliori rispetto a quelle che utilizzano sistemi di scrittura logografici o abugida. Il cinese, il coreano, il tamil e altre lingue hanno mostrato un'accuratezza moderata anche in contesti più brevi (e la loro accuratezza è peggiorata ulteriormente quando le sequenze sono diventate più lunghe). Questo completo 180 delle classifiche attese è interessante, perché la maggior parte degli LLM ampiamente diffusi sono addestrati principalmente su insiemi di dati pesanti per l'inglese. Tuttavia, i risultati del lavoro indicano che quando i modelli devono cercare, richiamare o riassumere informazioni sepolte in profondità all'interno di documenti lunghi, gli aspetti strutturali della lingua hanno la preferenza rispetto alla prevalenza del set di dati.
Anche altri risultati del benchmark supportano questa interpretazione. Il divario di prestazioni tra le lingue più forti e quelle più deboli cresce bruscamente con l'espansione del contesto - dall'11% a 8.000 tokens al 34% a 128.000 tokens. Un altro dettaglio dello studio mostra quanto questi test possano essere sensibili a piccole modifiche delle istruzioni. Per esempio, semplicemente permettendo al modello di rispondere "nessuno" se una stringa target è assente, l'accuratezza in inglese è diminuita del 32% a 128k tokens, come visibile a pagina 2.
Sebbene il benchmark confronti anche le famiglie di modelli, i risultati implicano che la valutazione dei contesti lunghi non può basarsi solo sui test in inglese e che le generalizzazioni delle prestazioni tra le lingue possono essere fuorvianti se si ignorano gli effetti di script e tokenizzazione. Man mano che le finestre di contesto diventano più grandi, le differenze linguistiche diventano più importanti, non meno - e la dominanza dell'inglese nei benchmark LLM potrebbe non essere più rappresentativa quando le lunghezze delle sequenze raggiungono le decine di migliaia.
Fonte(i)
Un righello per misurarli tutti: benchmarking dei modelli linguistici multilingue a contesto lungo al COLM 2025
Immagine in primo piano di Zulfugar Karimov su Unsplash

